在当今数据驱动的时代,大数据技术已成为企业数字化转型的关键引擎。许多求职者或从业者在简历上标榜“大数据专家”,却对Hadoop这一基础框架知之甚少,这不禁让人质疑其专业深度。Hadoop作为分布式系统领域的里程碑,不仅是数据处理与存储服务的核心,更是大数据生态的根基。
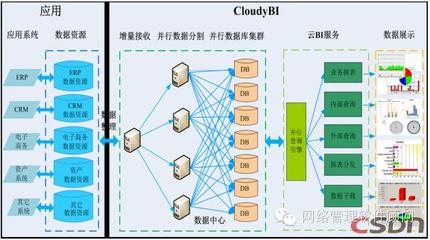
Hadoop解决了海量数据存储与计算的瓶颈。其分布式文件系统HDFS允许数据跨多台机器存储,提供高容错性;而MapReduce编程模型则实现了并行处理,使TB级数据的分析成为可能。例如,电商平台通过Hadoop集群分析用户行为日志,优化推荐算法;金融机构利用它进行风险建模,处理实时交易流。若缺乏Hadoop知识,如何设计可扩展的数据管道?又怎能理解数据分片、副本机制等关键概念?
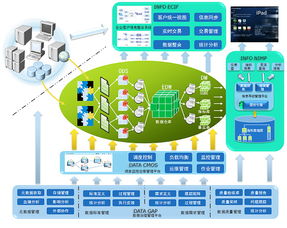
Hadoop生态圈衍生出众多工具,如Hive用于SQL查询、HBase支持实时读写,这些共同构成了完整的数据服务架构。一名合格的大数据工程师需熟悉Hadoop组件间的协同,例如用Sqoop从关系数据库导入数据至HDFS,再通过Spark进行高效计算。忽略Hadoop,无异于搭建高楼却忽视地基——可能短期内依赖云服务暂避复杂性,但长远来看,无法深入优化性能与成本。
更重要的是,Hadoop所代表的分布式思想是应对数据爆炸的基石。随着5G和物联网发展,数据量呈指数增长,企业需自建或管理混合云环境来保障数据主权与安全。Hadoop的开源特性及社区支持,使其成为定制化解决方案的首选。例如,医疗行业利用Hadoop存储基因组数据,确保合规的同时加速研究进程。
技术日新月异,云原生工具如Snowflake、Databricks逐渐兴起,但它们的底层逻辑常借鉴Hadoop的分布式理念。真正的大数据从业者应掌握Hadoop原理,方能灵活适配新技术。求职者若仅停留在API调用层面,而未深入Hadoop的架构设计,恐难在数据洪流中站稳脚跟。
Hadoop不仅是技术符号,更是大数据能力的试金石。在数据处理与存储服务领域,与其浮于表面追逐热词,不如夯实基础,从Hadoop出发,构建抵御数据浪潮的真实壁垒。